En este artículo:
- Comprender los núcleos tensores
- ¿Qué son los núcleos CUDA?
- ¿Qué son los núcleos sensores?
- ¿Cómo funcionan los núcleos sensores?
- Microarquitectura de GPU NVIDIA de primera generación
- Microarquitectura de GPU NVIDIA de segunda generación
- Microarquitectura de GPU NVIDIA de tercera generación
- Microarquitectura de GPU NVIDIA de cuarta generación
- Conclusión

Comprender los núcleos tensores
El núcleo tensorial de Nvidia es una tecnología crucial en las últimas versiones de la microarquitectura de GPU. Con cada generación, estas subunidades de procesamiento especializadas han avanzado desde su introducción en Volta, proporcionando un impulso significativo al rendimiento de la GPU a través del entrenamiento automático de precisión mixta.
Este artículo proporciona un resumen de las funciones del núcleo tensorial en las series Volta, Turing y Ampere de GPU NVIDIA. Al final del artículo, los lectores tendrán una idea clara de los diferentes tipos de núcleos de las GPU NVIDIA, cómo los núcleos Tensor facilitan el entrenamiento de precisión mixta para el aprendizaje profundo, cómo distinguir el rendimiento de los núcleos Tensor de cada microarquitectura y cómo reconocer las GPU dotadas de núcleos Tensor.
¿Qué son los núcleos CUDA?
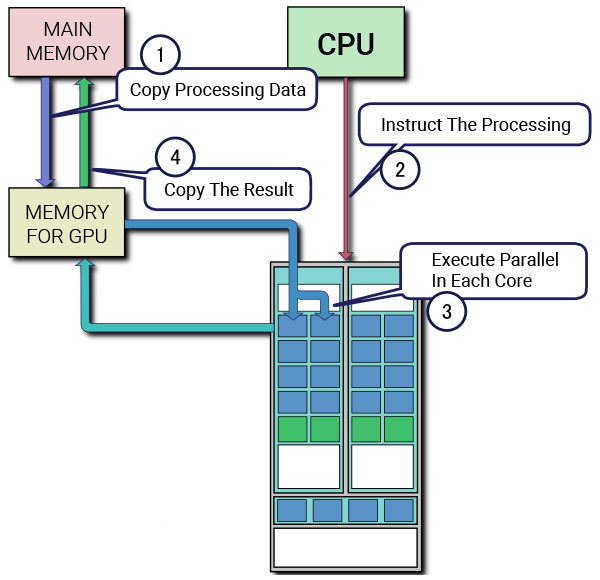
Para profundizar en la arquitectura y la utilidad de los núcleos tensoriales, es crucial entender los núcleos CUDA. La plataforma de procesamiento paralelo y API para GPU propiedad de NVIDIA, CUDA (Compute Unified Device Architecture), utiliza núcleos CUDA como unidad de coma flotante estándar en las tarjetas gráficas NVIDIA. Estos núcleos han sido una característica definitoria de las microarquitecturas de GPU NVIDIA durante la última década, presentes en todas las GPU NVIDIA lanzadas durante ese tiempo.
Cada núcleo CUDA realiza cálculos y ejecuta una operación por ciclo de reloj. Aunque no es tan potente como un núcleo de CPU, la utilización de varios núcleos CUDA en paralelo para el aprendizaje profundo puede acelerar enormemente los cálculos. En este artículo, exploraremos la relación entre CUDA y Tensor Cores, cómo trabajan juntos para permitir la computación de alto rendimiento y las características únicas de cada microarquitectura de GPU NVIDIA.
Antes de la introducción de los Tensor Cores, los núcleos CUDA eran el principal hardware utilizado para acelerar el aprendizaje profundo. Sin embargo, las GPU que dependen exclusivamente de los núcleos CUDA están limitadas por el número de núcleos disponibles y la velocidad de reloj de cada núcleo, ya que sólo pueden realizar un cálculo por ciclo de reloj. Para superar este cuello de botella, NVIDIA desarrolló el Tensor Core.
El Tensor Core revolucionó el rendimiento de la GPU al mejorar la capacidad de realizar cálculos de precisión mixta, aumentando la cantidad de datos que pueden procesarse simultáneamente. En esta entrada del blog, exploraremos las ventajas de los núcleos Tensor sobre los núcleos CUDA y cómo contribuyen a la alta computación en las últimas microarquitecturas de GPU de NVIDIA.
¿Qué son los núcleos sensores?
Los Tensor Cores son núcleos únicos diseñados para permitir la formación de precisión mixta en el aprendizaje profundo. La primera generación de Tensor Cores utiliza un cálculo fusionado de multiplicación y suma, que permite multiplicar y sumar dos matrices de 4×4 FP16 en una matriz de 4×4 FP16 o FP32.
El cálculo de precisión mixta se denomina así porque las matrices de entrada pueden ser FP16 de baja precisión, mientras que la matriz de salida es una FP32 de mayor precisión, lo que da lugar a cálculos más rápidos con una pérdida mínima de precisión. Esta característica mejora enormemente el rendimiento de los modelos de aprendizaje profundo.
A medida que avanzaba la tecnología, las microarquitecturas más recientes han ampliado las capacidades de los Tensor Cores para admitir formatos numéricos computacionales aún menos precisos, lo que acelera aún más los cálculos al tiempo que mantiene la eficacia del modelo. A continuación profundizaremos en los aspectos técnicos de los Tensor Cores y sus contribuciones a la computación de alto rendimiento en el aprendizaje profundo.
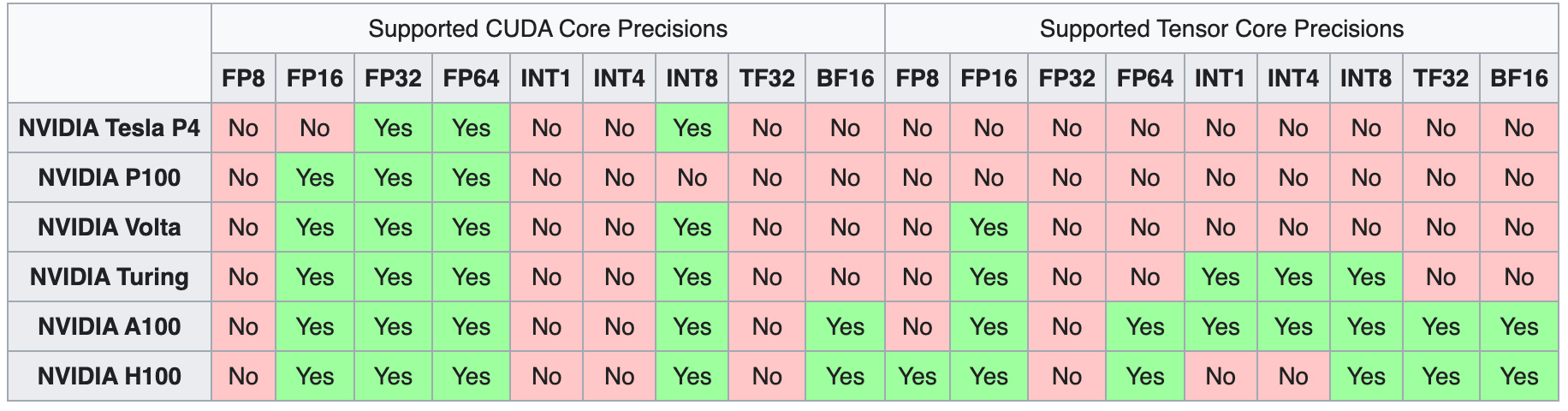
La introducción de la primera generación de Tensor Cores comenzó con la microarquitectura Volta, empezando por el V100. A medida que surgieron las generaciones posteriores, se equiparon con formatos de precisión numérica adicionales, ampliando la gama de cálculos que se pueden realizar.
En la siguiente sección, exploraremos las características únicas y las mejoras de cada microarquitectura en relación con los Tensor Cores y su impacto en la computación de alto rendimiento en el aprendizaje profundo.
¿Cómo funcionan los núcleos sensores?
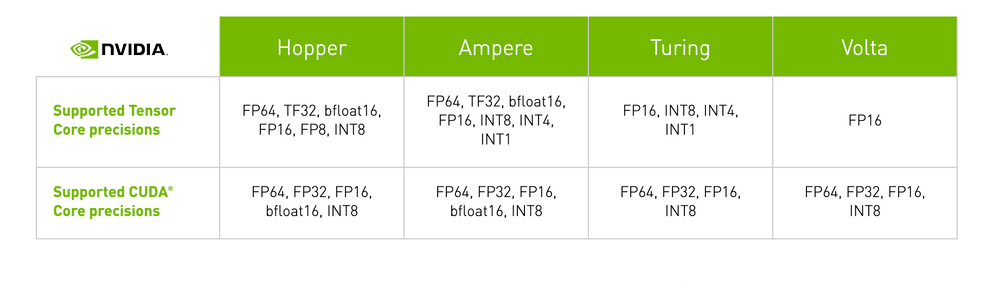
Con cada nueva generación de microarquitecturas de GPU, se han introducido nuevas metodologías para mejorar el rendimiento de las operaciones de los núcleos tensoriales. Estos avances han ampliado la gama de formatos numéricos con los que pueden operar los núcleos tensoriales, lo que se traduce en un aumento significativo del rendimiento de la GPU con cada iteración.
Microarquitectura de GPU NVIDIA de primera generación
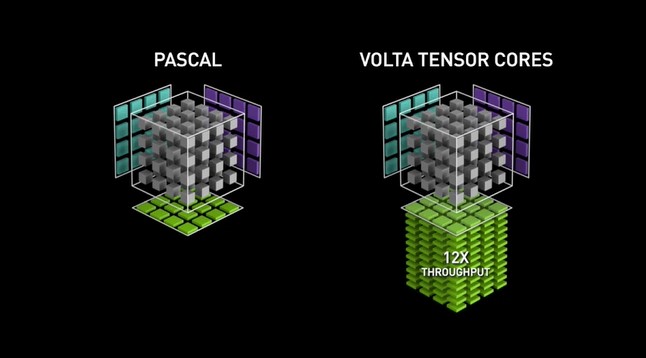
La microarquitectura de la GPU Volta marcó el debut de la primera generación de Tensor Cores, que facilitó el entrenamiento de precisión mixta utilizando el formato numérico FP16. Este desarrollo dio lugar a un enorme aumento potencial del rendimiento de hasta 12 veces en teraFLOPs. La emblemática V100, con sus 640 núcleos, proporcionó hasta 5 veces más velocidad de rendimiento en comparación con la anterior generación de GPU Pascal.
Microarquitectura de GPU NVIDIA de segunda generación
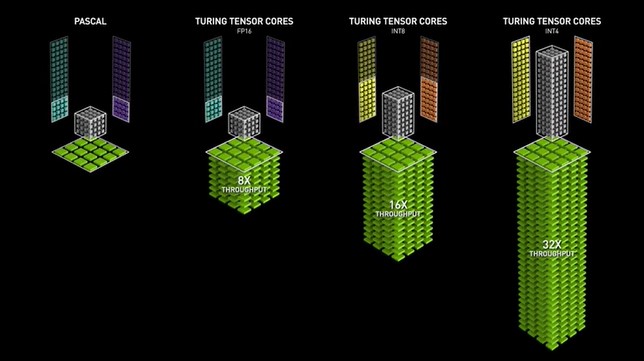
Las GPU Turing introdujeron la segunda generación de Tensor Cores, que admiten precisiones como Int8, Int4 e Int1 además de FP16. Estos Tensor Cores permiten realizar operaciones de entrenamiento de precisión mixta, lo que acelera el rendimiento de la GPU hasta 32 veces en comparación con las GPU Pascal. Las GPU Turing también incorporan núcleos de trazado de rayos, que mejoran propiedades de visualización gráfica como la luz y el sonido en entornos 3D.
Microarquitectura de GPU NVIDIA de tercera generación
La línea Ampere de GPUs cuenta con la tercera generación de Tensor Cores. Al ampliar la capacidad de cálculo a las precisiones FP64, TF32 y bfloat16, las GPU Ampere aceleran aún más las tareas de formación e inferencia del aprendizaje profundo. Con funciones como la especialización con matemáticas de matrices dispersas, NVLink de tercera generación y núcleos de Ray Tracing de tercera generación, las GPU Ampere -específicamente la A100 para centros de datos.
Los usuarios con un presupuesto ajustado también pueden aprovechar la potente microarquitectura Ampere y los núcleos Tensor Cores de tercera generación a través de la línea de GPU para estaciones de trabajo, como la A4000, la A5000 y la A6000. La implementación de la precisión mixta automática puede acelerar el entrenamiento en 2x adicionales con sólo unas pocas líneas de código.
La microarquitectura Ampere cuenta con funciones avanzadas como la especialización en matemáticas de matrices dispersas, NVLink de tercera generación para interacciones multi-GPU ultrarrápidas y núcleos de Ray Tracing de tercera generación.
Sin embargo, para aquellos con un presupuesto ajustado, la línea de GPU para estaciones de trabajo, como las A4000, A5000 y A6000, ofrecen una forma más asequible de acceder a la potente microarquitectura Ampere y sus núcleos sensores de tercera generación.
Microarquitectura de GPU NVIDIA de cuarta generación
En septiembre de 2022, NVIDIA lanzó la microarquitectura Hopper, que incluye la cuarta generación de Tensor Cores. Estos núcleos ofrecen mayor capacidad al añadir soporte para formatos de precisión FP8, lo que, según NVIDIA, puede acelerar los modelos de lenguaje de gran tamaño hasta 30 veces más que la generación anterior. La H100 es la primera GPU que incorpora estos nuevos Tensor Cores, lo que la convierte en una potente opción para quienes buscan lo último en tecnología de aprendizaje profundo.
Conclusión
Los avances tecnológicos de las GPU están estrechamente ligados a la evolución de la tecnología Tensor Core. Estos núcleos permiten realizar entrenamientos de precisión mixta de alto rendimiento y han hecho posible que las GPU Volta, Turing y Ampere se hayan convertido en las máquinas preferidas para el desarrollo de la IA. Como se describe en este artículo, el progreso de una generación de GPU a otra está marcado por las mejoras en las funciones de los núcleos Tensor Core.
Entender las capacidades y diferencias entre los Tensor Cores es crucial para comprender el significativo aumento de rendimiento que cada generación de GPU posterior aporta a las tareas de aprendizaje profundo. Al aprovechar estos potentes núcleos, cada generación, desde Volta hasta Hopper, ha allanado el camino para procesar cantidades cada vez más masivas de datos a una velocidad sin precedentes.










