En este artículo:
NVIDIA Jetson AGX Xavier para la nueva era de la IA en robótica
NVIDIA Jetson AGX Xavier ofrece 32 TeraOps para la nueva era de la inteligencia artificial en robótica.
La solución integrada más avanzada del mundo para desarrolladores de IA, Jetson AGX Xavier, ya está disponible en módulos de producción independientes de NVIDIA. Jetson AGX Xavier, que forma parte de los sistemas AGX de NVIDIA para máquinas autónomas, es ideal para implantar inteligencia artificial avanzada y visión por computador en los bordes, lo que permite a las plataformas robóticas sobre el terreno ofrecer un rendimiento similar al de las estaciones de trabajo y la capacidad de funcionar de forma totalmente autónoma sin depender de la intervención humana ni de la conectividad en la nube. Las máquinas inteligentes equipadas con Jetson AGX Xavier tienen la libertad de interactuar y navegar con seguridad en sus entornos, libres de obstáculos dinámicos y terrenos complejos, realizando tareas del mundo real con total autonomía. Esto incluye la entrega de paquetes y la inspección industrial, que requieren niveles avanzados de percepción e inferencia en tiempo real. Como primer ordenador del mundo diseñado específicamente para robótica y edge computing, el alto rendimiento de Jetson AGX Xavier puede manejar algoritmos de odometría visual, fusión de sensores, localización y mapeo, detección de obstáculos y planificación de trayectorias críticos para los robots de próxima generación. La foto de abajo muestra los módulos de computación de producción ya disponibles en todo el mundo. Los desarrolladores ya pueden empezar a desplegar nuevas máquinas autónomas en volumen.
 Módulo informático integrado Jetson AGX Xavier con placa de transferencia térmica (TTP), 100x87mm
Módulo informático integrado Jetson AGX Xavier con placa de transferencia térmica (TTP), 100x87mm
Jetson AGX Xavier, la última generación de la familia Jetson AGX de ordenadores Linux embebidos de alto rendimiento de NVIDIA, ofrece un rendimiento de clase estación de trabajo GPU con un incomparable máximo de 32 TeraOPS (TOPS) de cálculo y 750 Gbps de E/S de alta velocidad en un formato compacto de 100x87mm. Los usuarios pueden configurar los modos de funcionamiento a 10 W, 15 W y 30 W según necesiten para sus aplicaciones. Jetson AGX Xavier establece un nuevo listón en cuanto a densidad de cálculo, eficiencia energética y capacidades de inferencia de IA desplegables en el perímetro, lo que permite disponer de máquinas inteligentes de nuevo nivel con capacidades autónomas de extremo a extremo.
Jetson impulsa la IA detrás de muchos de los robots y máquinas autónomas más avanzados del mundo utilizando el aprendizaje profundo y la visión por ordenador, al tiempo que se centra en el rendimiento, la eficiencia y la programabilidad. Jetson AGX Xavier, cuyo diagrama se muestra en la siguiente figura, consta de más de 9.000 millones de transistores y se basa en el sistema en chip (SoC) más complejo jamás creado. La plataforma consta de una GPU NVIDIA Volta integrada de 512 núcleos que incluye 64 Tensor Cores, una CPU NVIDIA Carmel ARMv8.2 de 64 bits y 8 núcleos, 16 GB LPDDR4x de 256 bits, dos motores NVIDIA Deep Learning Accelerator (DLA), un motor NVIDIA Vision Accelerator, códecs de vídeo HD, 128 Gbps de ingesta de cámara dedicada y 16 carriles de expansión PCIe Gen 4. El ancho de banda de la memoria a través de la interfaz de 256 bits es de 137 GB/s, mientras que los motores DLA descargan la inferencia de las redes neuronales profundas (DNN). El SDK JetPack 4.1.1 de NVIDIA para Jetson AGX Xavier incluye CUDA 10.0, cuDNN 7.3 y TensorRT 5.0, lo que proporciona la pila completa de software de IA.
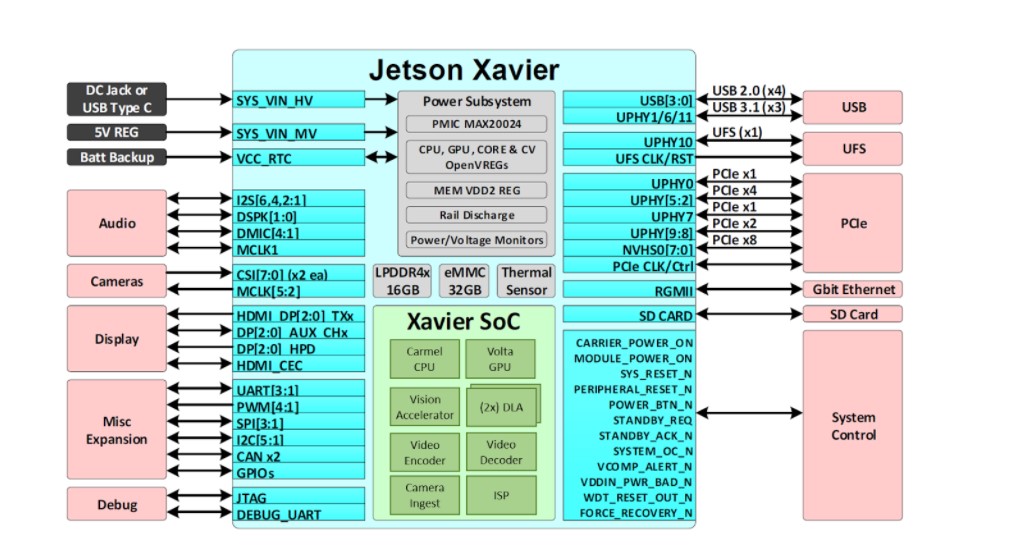 Jetson AGX Xavier ofrece un rico conjunto de E/S de alta velocidad
Jetson AGX Xavier ofrece un rico conjunto de E/S de alta velocidad
Esto permite a los desarrolladores la capacidad de desplegar IA acelerada en aplicaciones como robótica, análisis de vídeo inteligente, instrumentos médicos, dispositivos de borde IoT embebidos, etc. Al igual que sus predecesores Jetson TX1 y TX2, Jetson AGX Xavier utiliza un paradigma de sistema en módulo (SoM). Todo el procesamiento está integrado en el módulo de cálculo y las E/S de alta velocidad se alojan en un soporte o carcasa que se suministra a través de un conector de placa a placa de alta densidad. Esta forma de encapsular la funcionalidad en el módulo facilita a los desarrolladores la integración de Jetson Xavier en sus propios diseños. NVIDIA ha publicado una completa documentación y archivos de diseño de referencia que pueden descargarse los diseñadores de sistemas embebidos que deseen crear sus propios dispositivos y plataformas utilizando Jetson AGX Xavier.
Asegúrese de consultar la hoja de datos del módulo Jetson AGX Xavier y la guía de diseño de productos OEM Jetson AGX Xavier para conocer todas las características del producto que se enumeran en la tabla siguiente, además de las especificaciones electromecánicas, la disposición de los pines del módulo, la secuencia de alimentación y las directrices de direccionamiento de las señales.
|
Módulo NVIDIA Jetson AGX Xavier |
|
|
CPU |
aRMv8.2 de 64 bits NVIDIA Carmel de 8 núcleos a 2265 MHz |
|
GPU |
512 núcleos NVIDIA Volta a 1377 MHz con 64 TensorCores |
|
DL |
Aceleradores duales de aprendizaje profundo (DLA) de NVIDIA |
|
Memoria y almacenamiento |
16 GB LPDDR4x de 256 bits a 2133 MHz | 137 GB/s 32 GB eMMC 5.1 |
|
Visión |
(2x) Acelerador de visión VLIW de 7 vías |
|
Codificador |
(4x) 4Kp60 | (8x) 4Kp30 | (16x) 1080p60 | (32x) 1080p30Máximo rendimiento hasta (2x) 1000MP/s - H.265 Principal |
|
Principal* |
(2x) 8Kp30 | (6x) 4Kp60 | (12x) 4Kp30 | (26x) 1080p60 | (52x) 1080p30Máximo rendimiento hasta (2x) 1500MP/s - H.265 Principal |
|
Cámara† |
(16x) carriles MIPI CSI-2, (8x) carriles SLVS-EC; hasta 6 flujos de sensores activos y 36 canales virtuales |
|
Pantalla |
(3x) eDP 1.4 / DP 1.2 / HDMI 2.0 a 4Kp60 |
|
Ethernet |
ethernet 10/100/1000 BASE-T + MAC + interfaz RGMII |
|
USB |
(3x) USB 3.1 + (4x) USB 2.0 |
|
PCIe†† |
(5x) controladores PCIe Gen 4 | 1×8, 1×4, 1×2, 2×1 |
|
CAN |
Controlador de bus CAN doble |
|
E/S varias |
UART, SPI, I2C, I2S, GPIOs |
|
Zócalo |
conector placa a placa de 699 pines, 100x87mm con altura Z de 16mm |
|
Térmicos |
-25°C a 80°C |
|
Potencia |
perfiles de 10W / 15W / 30W, entrada de 9,0V-20VDC |
|
*Número máximo de flujos concurrentes hasta el rendimiento agregado. Códecs de vídeo compatibles: H.265, H.264, VP9Por favor, consulte la hoja de datos del módulo Jetson AGX Xavier §1.6.1 y §1.6.2 para especificaciones específicas de códec y perfil.+MIPI CSI-2, hasta 40 Gbps en D-PHY V1.2 o 109 Gbps en CPHY v1.1SLVS-EC, hasta 18,4 Gbps++(3x) controladores Root Port + Endpoint y (2x) controladores Root Port+Gama de temperaturas de funcionamiento, temperatura máxima de unión de la placa de transferencia térmica (TTP). |
|
Jetson AGX Xavier incluye más de 750 Gbps de E/S de alta velocidad, lo que proporciona una extraordinaria cantidad de ancho de banda para la transmisión de sensores y periféricos de alta velocidad. Es uno de los primeros dispositivos integrados compatibles con PCIe Gen 4, que proporciona 16 carriles a través de cinco controladores PCIe Gen 4, tres de los cuales pueden funcionar en modo de puerto raíz o de punto final. los 16 carriles MIPI CSI-2 pueden conectarse a cuatro cámaras de 4 carriles, seis cámaras de 2 carriles, seis cámaras de 1 carril o una combinación de estas configuraciones hasta seis cámaras, con 36 canales virtuales que permiten conectar más cámaras simultáneamente utilizando la agregación de flujos. Otras E/S de alta velocidad incluyen tres puertos USB 3.1, SLVS-EC, UFS y RGMII para Gigabit Ethernet. Los desarrolladores ya tienen acceso al software JetPack 4.1.1 Developer Preview de NVIDIA para Jetson AGX Xavier, que se indica en la tabla siguiente. La versión Developer Preview incluye Linux For Tegra (L4T) R31.1 Board Support Package (BSP) con soporte para Linux kernel 4.9 y Ubuntu 18.04 en el objetivo. En el PC host, JetPack 4.1.1 es compatible con Ubuntu 16.04 y Ubuntu 18.04.
|
Versión preliminar para desarrolladores de NVIDIA JetPack 4.1.1 |
|
|
L4T R31.0.1 (Linux K4.9) |
Ubuntu 18.04 LTS aarch64 |
|
CUDA Toolkit 10.0 |
cuDNN 7.3 |
|
TensorRT 5.0 GA |
GStreamer 1.14.1 |
|
VisionWorks 1.6 |
OpenCV 3.3.1 |
|
OpenGL 4.6 / GLES 3.2 |
Vulkan 1.1 |
|
Sistemas NVIDIA Nsight 2018.1 |
Gráficos NVIDIA Nsight 2018.6 |
|
API multimedia R31.1 |
API de cámara Argus 0.97 |
Componentes de software incluidos en JetPack 4.1.1 Developer Preview y L4T BSP para Jetson AGX Xavier
La versión JetPack 4.1.1 Developer Preview permite a los desarrolladores comenzar inmediatamente a crear prototipos de productos y aplicaciones con Jetson AGX Xavier como preparación para la implantación en producción. NVIDIA seguirá mejorando JetPack con nuevas funciones y optimizaciones del rendimiento. Lea las notas de la versión para conocer los aspectos más destacados y el estado del software de esta versión.
GPU Volta
La GPU Volta integrada en Jetson AGX Xavier, que se muestra en la figura 3, proporciona 512 núcleos CUDA y 64 núcleos sensores para un máximo de 11 TFLOPS FP16 o 22 TOPS de cálculo INT8, con una frecuencia de reloj máxima de 1,37 GHz. Admite CUDA 10 con una capacidad de cálculo de sm_72. La GPU incluye ocho multiprocesadores de flujo (SM) Volta con 64 núcleos CUDA y 8 núcleos sensores por SM Volta. Cada Volta SM incluye una caché L1 de 128 KB, 8 veces más que las generaciones anteriores. Los SM comparten una caché L2 de 512 KB y ofrecen un acceso 4 veces más rápido que las generaciones anteriores.
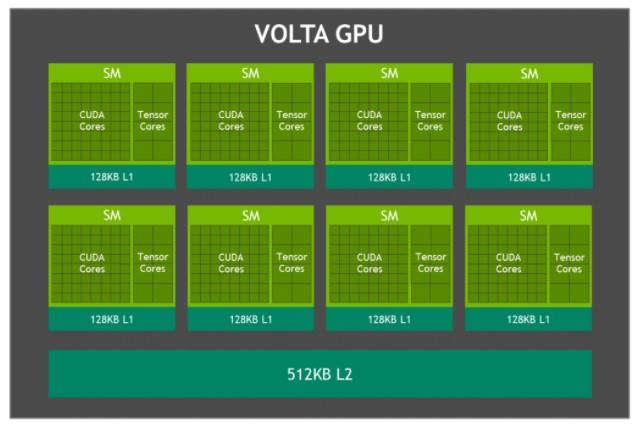 Diagrama de bloques de la GPU Jetson AGX Xavier Volta
Diagrama de bloques de la GPU Jetson AGX Xavier Volta
Cada SM consta de 4 bloques de procesamiento independientes denominados SMP (streaming multiprocessor partitions), cada uno de los cuales incluye su propia caché de instrucciones L0, programador de warps, unidad de envío y archivo de registro, junto con núcleos CUDA y núcleos tensoriales. Con el doble de SMP por SM que Pascal, el SM Volta presenta una concurrencia mejorada y admite más hilos, warps y bloques de hilos en vuelo.
Núcleos sensores
Los NVIDIA Tensor Cores son unidades programables de multiplicación y acumulación de matrices fusionadas que se ejecutan simultáneamente con los núcleos CUDA. Los Tensor Cores implementan nuevas instrucciones HMMA (Half-Precision Matrix Multiply and Accumulate) e IMMA (Integer Matrix Multiply and Accumulate) de coma flotante para acelerar cálculos de álgebra lineal densa, procesamiento de señales e inferencia de aprendizaje profundo.
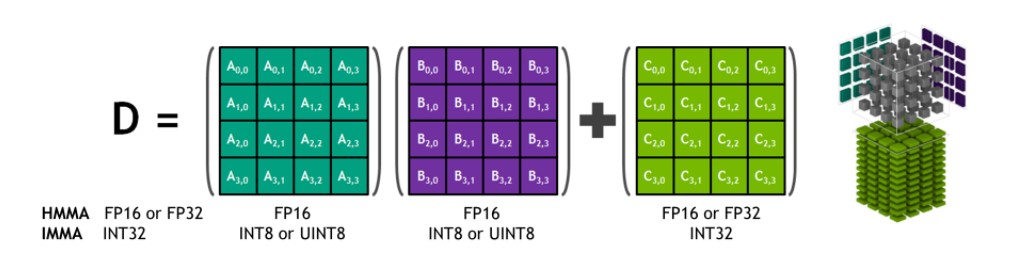
Tensor Core HMMA/IMMA Multiplicación y acumulación de matrices 4x4x4
Las entradas de multiplicación matricial A y B son matrices FP16 para las instrucciones HMMA, mientras que las matrices de acumulación C y D pueden ser matrices FP16 o FP32. Para IMMA, la entrada de multiplicación matricial A es una matriz INT8 o INT16 con signo o sin signo, B es una matriz INT8 con signo o sin signo, y las matrices de acumulación C y D son INT32 con signo. Por lo tanto, el rango de precisión y cálculo es suficiente para evitar condiciones de desbordamiento y subdesbordamiento durante la acumulación interna.
Las librerías de NVIDIA, incluidas cuBLAS, cuDNN y TensorRT, se han actualizado para utilizar internamente HMMA e IMMA, lo que permite a los programadores aprovechar fácilmente las mejoras de rendimiento inherentes a los Tensor Cores. Los usuarios también pueden acceder directamente a las operaciones del núcleo tensorial a nivel de warp a través de una nueva API expuesta en el espacio de nombres wmma y el encabezado mma.h incluidos en CUDA 10. La interfaz a nivel de warp asigna matrices de tamaño 16×16, 32×8 y 8×32 a los 32 subprocesos por warp.
Acelerador de aprendizaje profundo
Jetson AGX Xavier incluye dos motores del acelerador de aprendizaje profundo (DLA) de NVIDIA, que se muestran en el diagrama siguiente, que descargan la inferencia de las redes neuronales convolucionales (CNN) de función fija. Estos motores mejoran la eficiencia energética y liberan la GPU para ejecutar redes más complejas y tareas dinámicas implementadas por el usuario. La arquitectura de hardware de los DLA de NVIDIA es de código abierto y está disponible en NVDLA.org. Cada DLA tiene un rendimiento de hasta 5 TOPS INT8 o 2,5 TFLOPS FP16 con un consumo de energía de sólo 0,5-1,5W. Los DLA admiten la aceleración de capas de CNN como convolución, deconvolución, funciones de activación, agrupación de mín/máx/media, normalización de respuestas locales y capas totalmente conectadas.
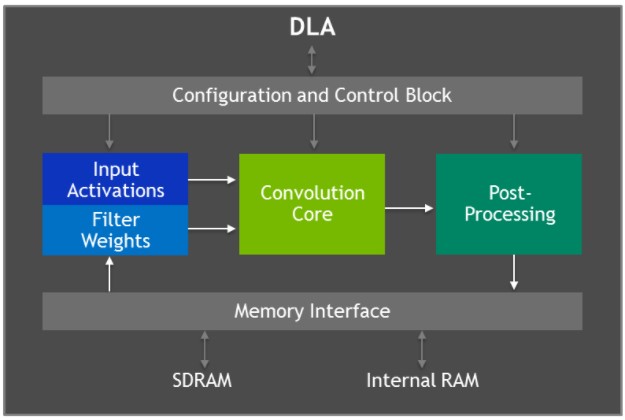 Diagrama de bloques de la arquitectura del acelerador de aprendizaje profundo (DLA)
Diagrama de bloques de la arquitectura del acelerador de aprendizaje profundo (DLA)
El hardware del DLA consta de los siguientes componentes
- Núcleo de convolución: motor de convolución optimizado de alto rendimiento.
- Procesador de datos simples: motor de búsqueda de punto único para funciones de activación.
- Procesador de datos planares: motor de promediado planar para la agrupación.
- Procesador de datos de canal: motor de promediado multicanal para funciones de normalización avanzadas.
- Dedicated Memory and Data Reshape Engines: aceleración de la transformación de memoria a memoria para operaciones de copia y remodelación de tensor.
Los desarrolladores programan motores DLA utilizando TensorRT 5.0 para realizar inferencias en redes, incluyendo soporte para AlexNet, GoogleNet y ResNet-50. Para redes que utilizan configuraciones de capas no soportadas por DLA, TensorRT proporciona GPU fallback para las capas que no pueden ser ejecutadas en DLAs. La versión JetPack 4.0 Developer Preview limita inicialmente la precisión de los DLA al modo FP16, mientras que la precisión INT8 y un mayor rendimiento de los DLA llegarán en una futura versión de JetPack.
TensorRT 5.0 añade las siguientes APIs a su interfaz IBuilder para habilitar los DLAs:
- Set Device Type() y set Default Device Type() para seleccionar GPU, DLA_0, o DLA_1 para la ejecución de una capa en particular, o para todas las capas de la red por defecto.
- Can Run On DLA() para comprobar si una capa puede ejecutarse en DLA según lo configurado.
- Get Max DLA Batch Size() para recuperar el tamaño máximo de lote que puede soportar DLA.
- Allow GPU Fallback() para permitir a la GPU ejecutar capas que DLA no soporta.
Pruebas de inferencias de aprendizaje profundo
Hemos publicado resultados de pruebas de inferencias de aprendizaje profundo para Jetson AGX Xavier en DNN comunes como variantes de ResNet, GoogleNet y VGG. Hemos ejecutado estas pruebas para Jetson AGX Xavier utilizando la versión JetPack 4.1.1 Developer Preview con TensorRT 5.0 en la GPU y los motores de DLA de Jetson AGX Xavier. La GPU y los dos ADL ejecutaron las mismas arquitecturas de red de forma simultánea con precisión INT8 y FP16 respectivamente, y se obtuvo el rendimiento agregado de cada configuración. La GPU y los ADL pueden ejecutar diferentes redes o modelos de red de forma simultánea en casos reales y desempeñar funciones únicas en paralelo o en un canal de procesamiento. El uso de INT8 frente a la precisión FP32 completa en TensorRT se traduce en una pérdida de precisión del 1% o menos.
En primer lugar, consideremos los resultados de ResNet-18 FCN (Fully Convolutional Network), que es un modelo full-HD con una resolución de 2048×1024 utilizado para la segmentación semántica. la segmentación proporciona una clasificación por píxel para tareas como la detección de espacios libres y el mapeo de ocupación, y es representativa de las cargas de trabajo de aprendizaje profundo calculadas por máquinas autónomas para la percepción, la planificación de rutas y la navegación. El gráfico siguiente muestra el rendimiento medido al ejecutar ResNet-18 FCN en Jetson AGX Xavier frente a Jetson TX2.
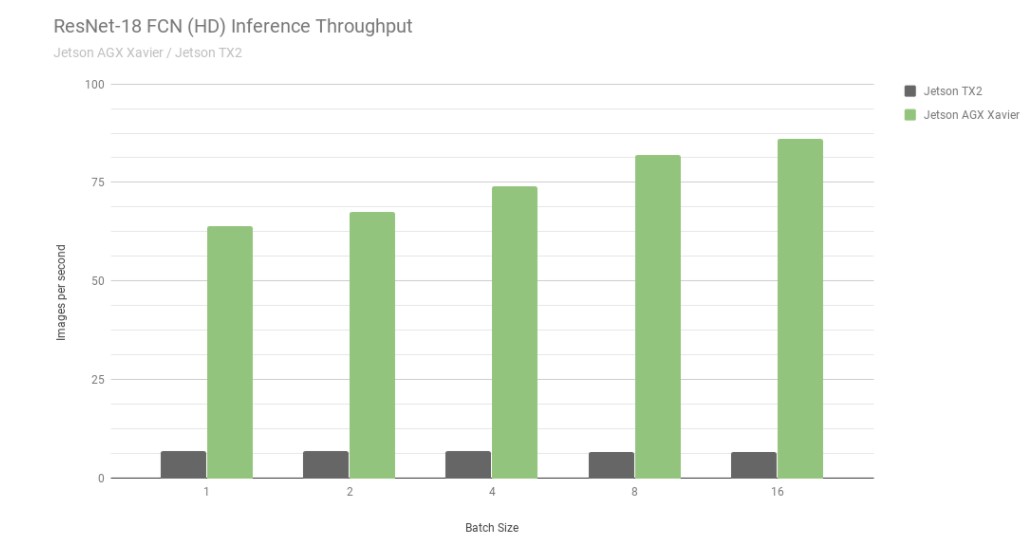 Rendimiento de inferencia de ResNet-18 FCN en Jetson AGX Xavier y Jetson TX2
Rendimiento de inferencia de ResNet-18 FCN en Jetson AGX Xavier y Jetson TX2
Actualmente, Jetson AGX Xavier consigue hasta 13 veces más rendimiento en la inferencia ResNet-18 FCN en comparación con Jetson TX2. NVIDIA seguirá publicando optimizaciones de software y mejoras de funciones en JetPack que seguirán mejorando el rendimiento y las características de consumo con el tiempo. tenga en cuenta que los listados completos de los resultados de las pruebas de rendimiento indican el rendimiento de ResNet-18 FCN para Jetson AGX Xavier hasta un tamaño de lote de 32, sin embargo, en el gráfico que aparece a continuación sólo representamos hasta un tamaño de lote de 16, ya que Jetson TX2 es capaz de ejecutar ResNet-18 FCN hasta un tamaño de lote de 16.
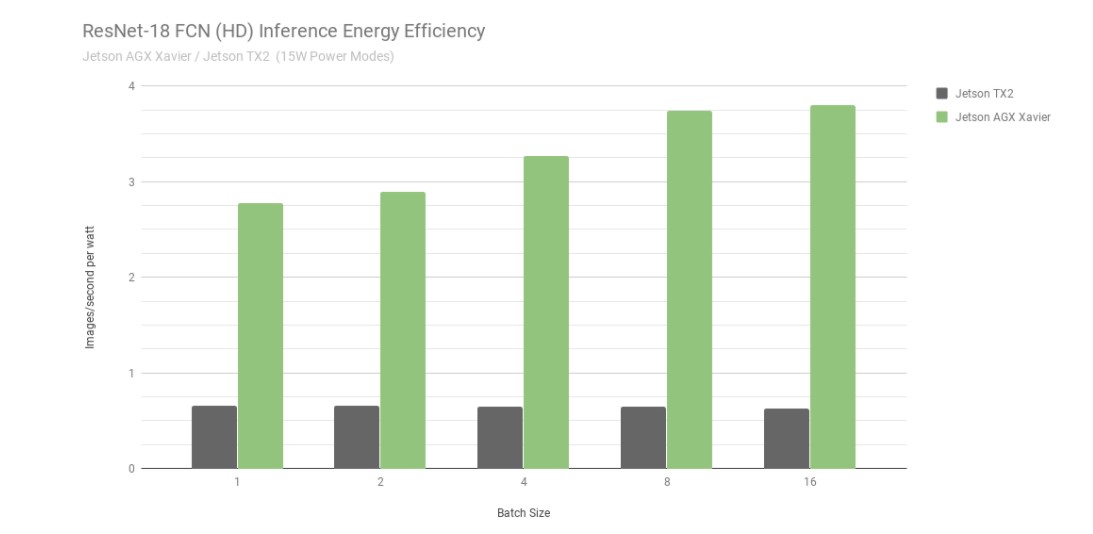
Eficiencia energética de la inferencia ResNet-18 FCN de Jetson AGX Xavier y Jetson TX2
Si tenemos en cuenta la eficiencia energética utilizando imágenes procesadas por segundo y vatio, Jetson AGX Xavier es hasta 6 veces más eficiente que Jetson TX2 en ResNet-18 FCN. Hemos calculado la eficiencia midiendo el consumo total de energía del módulo utilizando monitores de tensión y corriente INA integrados, incluido el consumo de energía de la CPU, la GPU, los DLA, la memoria, la energía del SoC, las E/S y las pérdidas de eficiencia del regulador en todos los raíles. Ambos Jetson se ejecutaron en modo de alimentación de 15 W. Jetson AGX Xavier y JetPack se suministran con perfiles de consumo configurables de 10, 15 y 30 W, que se pueden cambiar en tiempo de ejecución mediante la herramienta de gestión de consumo nvpmodel. Los usuarios también pueden definir sus propios perfiles personalizados con diferentes relojes y ajustes del regulador DVFS (Dynamic Voltage and Frequency Scaling) que se han adaptado para lograr el mejor rendimiento para aplicaciones individuales.
A continuación, vamos a comparar las pruebas de Jetson AGX Xavier con las redes de reconocimiento de imágenes ResNet-50 y VGG19 en los tamaños de lote 1 a 128 frente a Jetson TX2. Estos modelos clasifican parches de imágenes con una resolución de 224×224 y se utilizan con frecuencia como columna vertebral del codificador en diversas redes de detección de objetos. El uso de un tamaño de lote de 8 o superior a la resolución más baja puede servir para aproximarse al rendimiento y la latencia de un tamaño de lote de 1 a resoluciones más altas. Las plataformas robóticas y las máquinas autónomas incorporan a menudo múltiples cámaras y sensores que pueden procesarse por lotes para aumentar el rendimiento, además de realizar la detección de regiones de interés (ROI) seguida de una clasificación posterior de las ROI por lotes. La siguiente figura también incluye estimaciones del rendimiento futuro de Jetson AGX Xavier, que incorporan mejoras de software como la compatibilidad de INT8 con DLA y optimizaciones adicionales para la GPU.
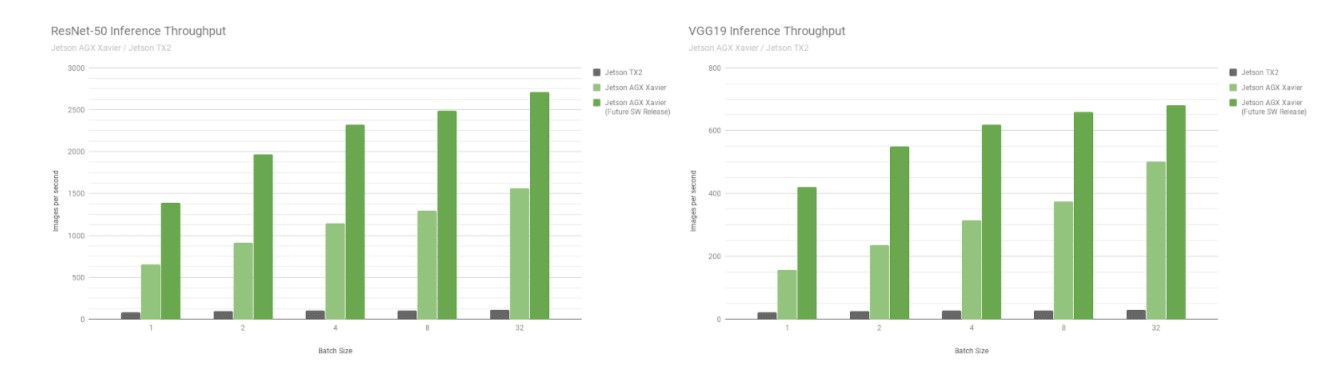 Rendimiento estimado tras la compatibilidad con INT8 para DLA y optimizaciones adicionales para la GPU
Rendimiento estimado tras la compatibilidad con INT8 para DLA y optimizaciones adicionales para la GPU
Jetson AGX Xavier alcanza actualmente hasta 18 veces el rendimiento de Jetson TX2 en VGG19 y 14 veces en ResNet-50 medido ejecutando el JetPack 4.1.1, como se muestra en la siguiente figura. La latencia de ResNet-50 es tan baja como 1,5 ms, o más de 650 FPS con un tamaño de lote de 1. Se estima que Jetson AGX Xavier será hasta 24 veces más rápido que Jetson TX2 con futuras mejoras de software. Ten en cuenta que para las comparaciones heredadas también proporcionamos datos para GoogleNet y AlexNet en los listados completos de rendimiento.
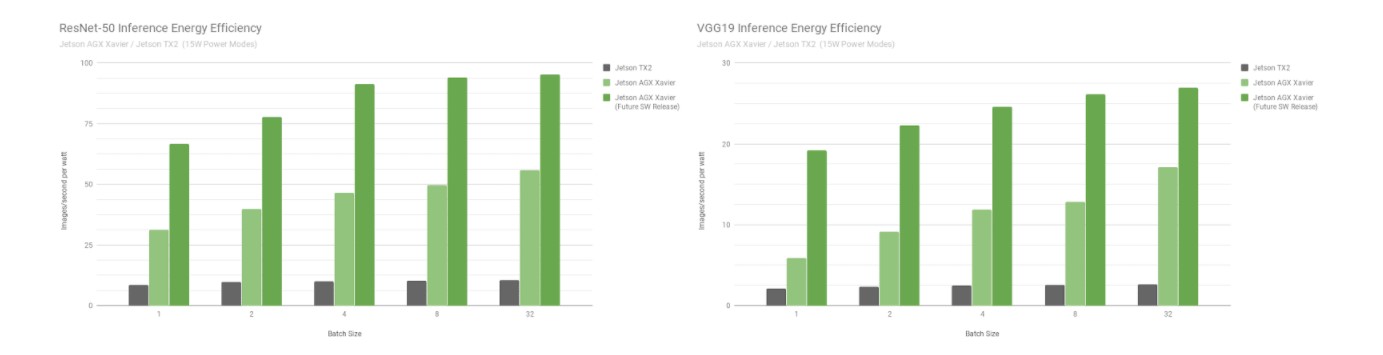 Eficiencia energética de ResNet-50 y VGG19 para Jetson Xavier y Jetson TX2
Eficiencia energética de ResNet-50 y VGG19 para Jetson Xavier y Jetson TX2
Jetson AGX Xavier es actualmente más de 7 veces más eficiente en la inferencia VGG19 que Jetson TX2 y 5 veces más eficiente con ResNet-50, con un aumento de hasta 10 veces en la eficiencia cuando se consideran futuras optimizaciones y mejoras de software. Consulta los resultados de rendimiento completos para obtener más datos y detalles sobre las pruebas de inferencia. En la siguiente sección también se evalúa el rendimiento de la CPU.
Complejo CPU Carmel
El complejo de CPU de Jetson AGX Xavier, como se muestra en la siguiente foto, consta de cuatro clústeres heterogéneos de CPU NVIDIA Carmel de doble núcleo basados en ARMv8.2 con una frecuencia de reloj máxima de 2,26 GHz. Cada núcleo incluye cachés L1 de 128 KB de instrucciones y 64 KB de datos, además de una caché L2 de 2 MB compartida entre los dos núcleos. Los núcleos de la CPU comparten una caché L3 de 4 MB.

Diagrama de bloques del complejo de CPU Jetson Xavier con clusters NVIDIA Carmel
Los núcleos de la CPU Carmel incorporan la optimización dinámica de código de NVIDIA, una arquitectura superescalar de 10 vías y una implementación completa de ARMv8.2 que incluye SIMD avanzada, VFP (punto flotante vectorial) y ARMv8.2-FP16.
La prueba SPECint_rate mide el rendimiento de la CPU en sistemas multinúcleo. La puntuación de rendimiento global promedia varias subpruebas intensivas, como compresión, operaciones vectoriales y gráficas, compilación de código y ejecución de IA para juegos como ajedrez y Go. La siguiente figura muestra los resultados de las pruebas con un aumento de más de 2,5 veces en el rendimiento de la CPU entre generaciones.
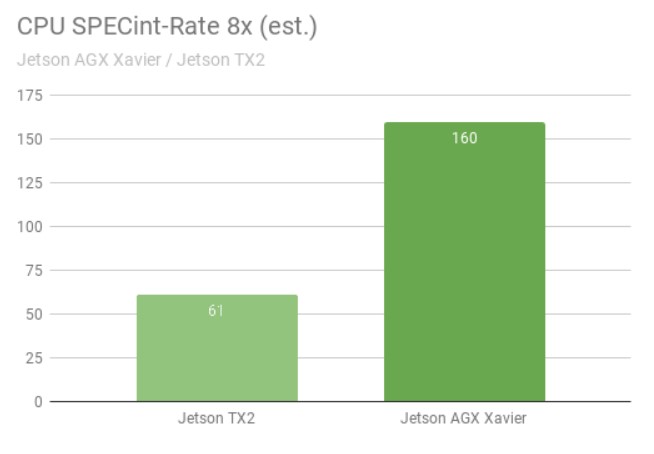 Rendimiento de la CPU de Jetson AGX Xavier cs. Jetson TX2 en la prueba SPECint
Rendimiento de la CPU de Jetson AGX Xavier cs. Jetson TX2 en la prueba SPECint
Se ejecutaron ocho copias simultáneas de las pruebas SPECint_rate, manteniendo las CPU totalmente cargadas. Jetson AGX Xavier tiene naturalmente ocho núcleos de CPU; la arquitectura de Jetson TX2 utiliza cuatro núcleos Arm Cortex-A57 y dos núcleos NVIDIA Denver D15. Si se ejecutan dos copias por núcleo Denver, el rendimiento es mayor.
Acelerador de visión
Jetson AGX Xavier cuenta con dos motores de acelerador de visión, que se muestran en la siguiente figura. Cada uno de ellos incluye un procesador vectorial VLIW (Very Long Instruction Word) dual de 7 vías que descarga algoritmos de visión por ordenador como la detección y correspondencia de rasgos, el flujo óptico, la correspondencia de bloques de disparidad estereoscópica y el procesamiento de nubes de puntos con baja latencia y bajo consumo. También son ideales para la aceleración filtros de imagen como convoluciones, operadores morfológicos, histogramación, conversión del espacio de color y warping.
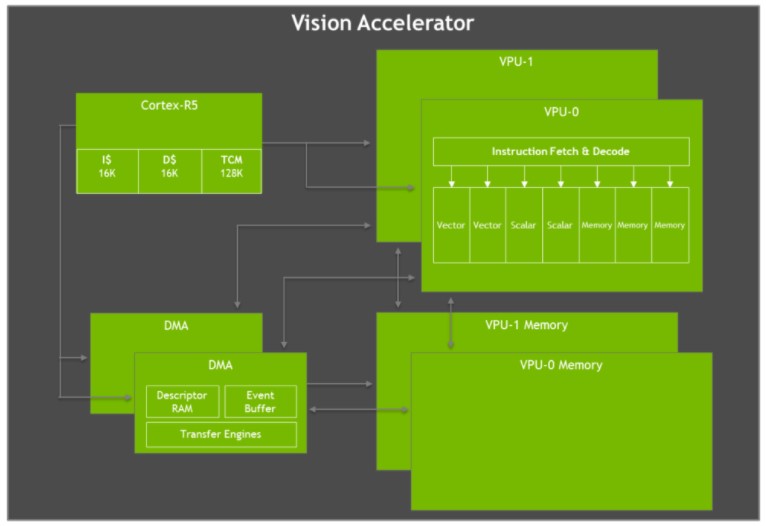 Diagrama de bloques de la arquitectura del acelerador de visión VLIW Jetson AGX Xavier
Diagrama de bloques de la arquitectura del acelerador de visión VLIW Jetson AGX Xavier
Cada acelerador de visión incluye un núcleo Cortex-R5 para mando y control, dos unidades de procesamiento vectorial (cada una con 192 KB de memoria vectorial en chip) y dos unidades DMA para movimiento de datos. Las unidades de procesamiento vectorial de 7 vías contienen ranuras para dos operaciones vectoriales, dos escalares y tres de memoria por instrucción. La versión de software Early Access carece de soporte para el acelerador de visión, pero se habilitará en una futura versión de JetPack.
Kit de desarrollo NVIDIA Jetson AGX Xavier
El kit de desarrollo Jetson AGX Xavier contiene todo lo necesario para que los desarrolladores puedan empezar a trabajar rápidamente. El kit incluye el módulo de cálculo Jetson AGX Xavier, la placa base de código abierto de referencia, la fuente de alimentación y el kit de desarrollo de software JetPack, lo que permite a los usuarios empezar a desarrollar aplicaciones rápidamente.

Kit de desarrollo Jetson AGX Xavier, que incluye el módulo Jetson AGX Xavier y la placa base de referencia.
Con 105 mm2, el kit de desarrollo Jetson AGX Xavier es significativamente más pequeño que los kits de desarrollo Jetson TX1 y TX2, al tiempo que mejora la E/S disponible. Las capacidades de E/S incluyen dos puertos USB3.1 (compatibles con DisplayPort y Power Delivery), un puerto híbrido eSATAp + USB3.0, una ranura PCIe x16 (x8 eléctrica), sitios para mezzanines M.2 Key-M NVMe y M.2 Key-E WLAN, Gigabit Ethernet, HDMI 2.0 y un conector MIPI CSI para 8 cámaras. Consulte la Tabla 3 a continuación para obtener una lista completa de las E/S disponibles a través de la placa base de referencia del kit de desarrollo
|
E/S del kit de desarrollo |
Interfaz del módulo Jetson AGX Xavier |
|
PCIe x16 |
PCIe x8 Gen 4/ SLVS x8 |
|
RJ45 |
Gigabit Ethernet |
|
USB-C |
2x USB3.1 (DisplayPort opcional) (Power Delivery opcional) |
|
Conector de cámara |
16x carriles MIPI CSI-2, hasta 6 flujos de sensores activos |
|
Clave M.2 |
NVMe x4 |
|
Clave M.2 E |
PCIe x1 (para Wi-Fi/ LTE/ 5G) + USB2 + UART + I2S/PCM |
|
cabezal de 40 pines |
UART + SPI + CAN + I2C + I2S + DMIC + GPIOs |
|
Cabecera HD Audio |
Audio de alta definición |
|
eSATAp + USB 3.0 |
SATA mediante puente PCIe x1 (alimentación + datos para SATA de 2,5") + USB 3.0 |
|
HDMI tipo A |
HDMI 2.0, Edp 1.2A, DP 1.4 |
|
Ranura para tarjetas SD/UFS |
SD/UFS |
Puertos de E/S disponibles en el kit de desarrollo Jetson AGX Xavier
Análisis inteligente de vídeo (IVA)
La IA y el aprendizaje profundo permiten utilizar de forma eficaz grandes cantidades de datos para mantener las ciudades más seguras y cómodas, lo que incluye aplicaciones como la gestión del tráfico, el aparcamiento inteligente y la agilización de la experiencia de pago en tiendas minoristas. NVIDIA Jetson y NVIDIA DeepStream SDK permiten que las cámaras inteligentes distribuidas realicen análisis de vídeo inteligentes en el perímetro en tiempo real, lo que reduce la enorme carga de ancho de banda que soporta la infraestructura de transmisión y mejora la seguridad junto con el anonimato.
Jetson TX2 puede procesar dos flujos HD simultáneamente con detección y seguimiento de objetos. Como se muestra en el vídeo anterior, Jetson AGX Xavier es capaz de manejar 30 flujos de vídeo HD independientes simultáneamente a 1080p30, lo que supone una mejora de 15 veces. Jetson AGX Xavier ofrece un rendimiento total de más de 1850 MP/s, lo que le permite descodificar, preprocesar, realizar inferencias con detección basada en ResNet y visualizar cada fotograma en poco más de 1 milisegundo. Las capacidades de Jetson AGX Xavier aportan niveles muy superiores de rendimiento y escalabilidad a la analítica de vídeo periférica.
Una nueva era de autonomía
Jetson AGX Xavier ofrece niveles de rendimiento sin precedentes a bordo de robots y máquinas inteligentes. Estos sistemas requieren una exigente capacidad de cálculo para la percepción, navegación y manipulación basadas en IA con el fin de proporcionar un funcionamiento autónomo robusto. Entre sus aplicaciones se incluyen la fabricación, la inspección industrial, la agricultura de precisión y los servicios a domicilio. Los robots autónomos de reparto que entregan paquetes a los consumidores finales y apoyan la logística en almacenes, tiendas y fábricas representan una clase de aplicación.
Un proceso típico de reparto y logística totalmente autónomos requiere varias fases de tareas de visión y percepción, como se muestra en la figura siguiente. Los robots de reparto móviles suelen tener varias cámaras HD periféricas que proporcionan un conocimiento de la situación de 360°, además de LIDAR y otros sensores de alcance que se fusionan en el software junto con los sensores inerciales. A menudo se utiliza una cámara de conducción estereoscópica orientada hacia delante, que requiere preprocesamiento y mapeo de profundidad estereoscópica. Para ello, NVIDIA ha creado modelos DNN estereoscópicos con mayor precisión que los métodos tradicionales de emparejamiento de bloques.
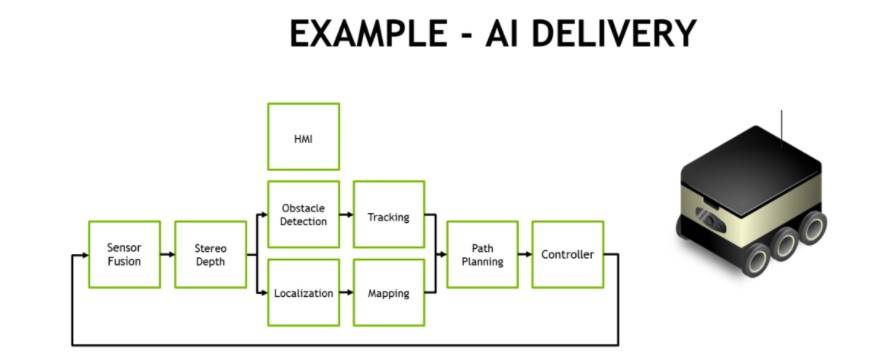 Ejemplo de canal de procesamiento de IA de un robot autónomo de reparto y logística
Ejemplo de canal de procesamiento de IA de un robot autónomo de reparto y logística
Los modelos de detección de objetos como SSD o Faster-RCNN y el seguimiento basado en características suelen servir para evitar obstáculos, como peatones, vehículos y puntos de referencia. En el caso de los robots de almacén y tienda, estos modelos de detección de objetos localizan elementos de interés como productos, estanterías y códigos de barras. El reconocimiento facial, la estimación de la postura y el reconocimiento automático del habla (ASR) facilitan la interacción hombre-máquina (HMI) para que el robot pueda coordinarse y comunicarse eficazmente con los humanos.
La localización y el mapeo simultáneos (SLAM) de alta velocidad son fundamentales para mantener al robot actualizado con una posición precisa en 3D. El GPS por sí solo carece de precisión para el posicionamiento submétrico y no está disponible en interiores. El SLAM realiza el registro y la alineación de los datos más recientes de los sensores con los datos anteriores que el sistema ha acumulado en su nube de puntos. Los datos de los sensores, a menudo ruidosos, requieren un filtrado considerable para localizarlos correctamente, sobre todo los procedentes de plataformas en movimiento.
La fase de planificación de trayectorias suele utilizar redes de segmentación semántica como ResNet-18 FCN, SegNet o DeepLab para realizar la detección de espacios libres, indicando al robot por dónde circular sin obstáculos. En el mundo real existen con frecuencia demasiados tipos de obstáculos genéricos para detectarlos y seguirlos individualmente, por lo que un enfoque basado en la segmentación etiqueta cada píxel o vóxel con su clasificación. Junto con las etapas anteriores del proceso, esto informa al planificador y al bucle de control de las rutas seguras que puede tomar.
El rendimiento y la eficiencia de Jetson AGX Xavier permiten procesar a bordo todos los componentes necesarios en tiempo real para que estos robots funcionen de forma segura con plena autonomía, incluidos los algoritmos de visión de alto rendimiento para la percepción, navegación y manipulación en tiempo real. Los módulos Jetson AGX Xavier independientes ya están en producción, por lo que los desarrolladores pueden implantar estas soluciones de IA en la próxima generación de máquinas autónomas.
Assured Systems y NVIDIA Jetson AGX Xavier
En Assured Systems suministramos una amplia gama de productos Jetson, incluidos los basados en Jetson AGX Xavier, que aportan niveles de computación revolucionarios a la robótica y los dispositivos de vanguardia, con un rendimiento de estación de trabajo de gama alta en una plataforma integrada optimizada en cuanto a tamaño, peso y potencia.
Póngaseen contacto con nosotros para solicitar información sobre su proyecto.










